Представление процессов в ядре
Для отслеживания процессов ядро использует несколько структур данных; некоторые из них связанны с представлением самого процесса, а некоторые являются отдельными. Эти структуры данных показаны на рис. 7.2 и подробно описаны далее в этой главе.

Рис. 7.2. Структуры данных ядра, предназначенные для управления задачами
Процесс представляется структурой данных ядра struct task_struct. Советуем по крайней мере просмотреть определение этой структуры. Она достаточно велика, но логически организована в виде отдельных модулей, смысл которых станет понятен по мере прочтения этой главы. А пока, обратите внимание, что многие составные части этой структуры являются указателями на другие структуры; это пригодится, когда дочерней и родительской структурам потребуется совместно использовать указываемую информацию — многие указатели указывают на информацию, для которой выполняется подсчет ссылок.
Сами задачи образуют циклический, дважды связанный список, называемый списком задач, использующий члены next_task и prev_task структуры struct task_struct. Да, это так, не смотря на то, что они уже доступны в центральном массиве task (который вскоре будет описан). Вначале это может показаться странным, но в действительности имеет большой смысл, поскольку позволяет коду ядра осуществлять итерации по всем существующим задачам — т.е. всем заполненным слотам в массиве task — не тратя время на явный пропуск пустых слотов. Действительно, эта итерация требуется столь часто, что для нее существует макрос: for_each_task в строке .
Хотя он содержит всего одну строку, макрос for_each_task имеет несколько заслуживающих внимания особенностей. Во-первых, обратите внимание, что он использует член init_task в качестве начала и конца итерации. Это совершенно безопасно, поскольку init_task никогда не осуществляет выход; следовательно, он всегда доступен для использования в качестве маркера. Однако обратите внимание, что сам член init_task не посещается во время итерации, что иногда желательно во время использования макроса. Обратите также внимание, что посредством использования члена next_task в списке всегда выполняется продвижение вперед; не существует никакого макроса для перемещения назад. Это и не нужно — член prev_task требуется только для эффективного удаления задачи из списка.
Linux поддерживает еще один циклический, дважды связанный список задач, аналогичный описанному перед этим. Этот список использует члены prev_run и next_run структуры struct task_struct и в целом обрабатывается как очередь (gesundheight); по этой причине данный список обычно называется текущей очередью. Как и в случае с членом prev_task, член prev_run нужен только для эффективного удаления задачи из очереди; итерация по списку всегда выполняется в прямом направлении посредством использования члена next_run. Кроме того, как и в случае обычного списка задач, член init_task используется для отметки начала и конца очереди.
Задачи добавляются в очередь с помощью функции add_to_runqueue (строка ) и удаляются с помощью функции del_from_runqueue (строка ). Иногда они также перемещаются в начало или в конец очереди соответственно с помощью функций move_first_runqueue (строка ) и move_last_runqueue (строка ). Обратите внимание, что все эти функции являются локальными для kernel/sched.c, а поля prev_run и next_run не используются ни в каких других файлах (за исключением файла kernel/fork.c во время процесса создания); это достаточно оправдано, поскольку текущая очередь требуется только для планирования.
На основе этого задачи образуют граф, структура которого выражает родственные взаимосвязи между задачами; поскольку я не знаю никакого общепринятого термина для этого графа, я называю его графом процессов. Граф практически не зависит от связи next_task/prev_task в которой позиция задачи почти не имеет смысла — так уж сложилось исторически. Каждая структура struct task_struct поддерживает пять указателей самой позиции внутри графа процессов. Эти пять указателей объявляются в строках – :
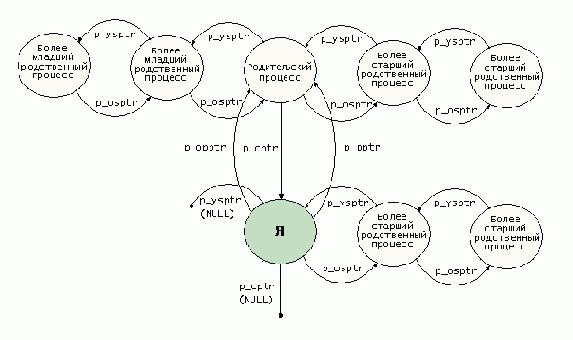
Рис. 7.3. Граф процессов
Эти взаимосвязи показаны на рис. 7.3 (полный набор связей показан только для узла, обозначенного Я). Этот набор указателей обеспечивает еще один способ перемещения по набору процессов в системе; совершено очевидно, что указатели наиболее полезны при таких перемещениях, как поиск родительского процесса или перемещение по списку дочерних процессов данного процесса. Указатели поддерживаются двумя макросами:
Оба эти макроса также настраивают связи next_task/prev_task. Если вы внимательно исследуете макросы, то увидите, что они могут добавлять или удалять только процессы-листья, но не процессы, имеющие дочерние процессы.
task определяется как массив указателей на структуру struct task_structs. Каждая задача в системе представляется записью в этом массиве. Массив имеет размер NR_TASKS (в строке это значение установлено равным 512), устанавливая верхний предел количества задач, которые могут выполняться одновременно. Поскольку существует 32768 возможных PID, этот массив явно недостаточно велик, чтобы непосредственно индексировать все задачи в системе по их PID. (Т.е. элемент массива task[i] не обязательно будет задачей, имеющей PID i.) Вместо этого Linux использует другие структуры данных, помогающие в управлении этим ограниченным ресурсом.
Список свободных слотов tarray_freelist поддерживает список (в действительности являющийся стеком) свободных позиций в массиве task. Он инициализируется в строках и , а затем манипулирование им осуществляется с помощью двух внутренних функций, определенных в строках с по . В SMP доступ к списку tarray_freelist должен ограничиваться блокировкой taskslot_lock (строка ). (Блокировки подробно описаны в .)
Массив pidhash помогает отображать PID указателями на структуру struct task_structs. pidhash инициализируется в строках и , после чего манипулирование им осуществляется с помощью набора макросов и внутренних функций, определенных в строках с по . Тем самым просто реализуется лишенная коллизий хэш-таблица. Обратите внимание, что функции, поддерживающие pidhash, используют два члена в самой структуре struct task_struct — pidhash_next (строка ) и pidhash_pprev (строка ) — для поддержания областей хеша. С помощью pidhash ядро может эффективно находить задачу по ее PID, хотя эта операция выполняется и не так быстро, как могла бы выполняться при непосредственном поиске.
Просто ради развлечения, убедитесь, что функция хеша — pid_hashfh в строке — обеспечивает равномерное распределение по своей области от 0 до 32767 (по всем допустимым PID). Если читатели имеют иное представление о развлечении, что ж, так тому и быть.
Эти структуры данных обеспечивают массу информации о действующей системе, но это не дается даром: все эти структуры должны корректно поддерживаться при каждом добавлении или удалении процессов; в противном случае порядок в системе будет нарушен. Трудность этого является одной из причин, по которой процессы создаются (функцией do_fork, которая описана далее в этой главе) и удаляются (функцией release, также описанной далее) в одном месте.
Эту сложность можно было бы уменьшить, по крайней мере частично, если просто сделать task массивом 32768 структур struct task_structs, по одной для каждого возможного PID. Но это значительно увеличило бы требования к объему памяти ядра. Единственная структура struct task_structs занимает 964 байта в однопроцессорной и 1212 байт в SMP-системе — округленно, около 1 Кб. Для хранения 32768 структур массиву task потребовалась бы память объемом 32768 Кб или 32 Мб! (В действительности все гораздо хуже: дополнительная память, связанная с поддержкой задач, которая еще не была освещена, увеличивает эту цифру в 8 раз — т.е. до 256 Мб — и все это еще без действительного выполнения какой-либо из задач.) Кроме того, аппаратная часть системы управления памятью х86 ограничивает количество активных задач приблизительно до 4000; эта тема освещена в следующей главе. Таким образом, большая часть ячеек в таком массиве неизбежно расходовалась бы напрасно.
По существу task — это всего лишь 512 4-разрядных указателей, которые занимают всего 2 Кб памяти, если ни одна из задач не выполняется. Все вспомогательные структуры данных занимают небольшой дополнительный объем памяти, но это все же значительно меньше 32 Мб. Даже в случае заполнения всех слотов в массиве task и при резервировании памяти для всех структур struct task_struct общий объем занятой памяти составляет всего около 512 Кб. В случае кармана приложений картина меняется.